前不久,在中文语言理解权威评测基准CLUE中,阿里巴巴的AI模型在新闻文本上超越了人类识别精确度。现在“读图会意”上,阿里巴巴达摩院在VQA上也超越了人类,这是榜单设立6年来的首次。
8月12日,国际权威机器视觉问答榜单VQA Leaderboard出现关键突破:阿里巴巴达摩院以81.26%的准确率创造了新纪录,让AI在“读图会意”上首次超越人类基准。
继2015年、2018年AI分别在视觉识别及文本理解领域超越人类分数后,人工智能在多模态技术领域也迎来一大进展。
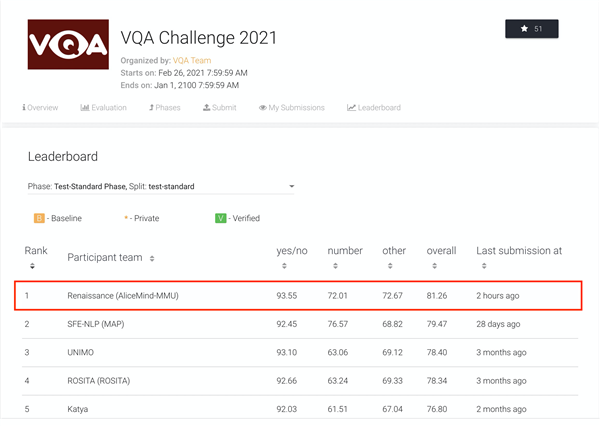
达摩院AliceMind在VQA Leaderboard上创造首次超越人类的纪录
“诗是无形画,画是有形诗。”宋代诗人张舜民曾描绘语言与视觉的相通之处。“读图会意”,即通过视觉理解信息,是人类的一项基础能力,但对AI来说却是要求极高的认知任务。
解决该挑战,对研发通用人工智能有重要意义。近10年来,AI在下棋、视觉、文本理解等单模态技能上突飞猛进,但在涉及视觉-文本跨模态理解的高阶认知任务上,AI过去始终未达到人类水平。
为攻克这一难题而设立的挑战赛VQA Challenge,自2015年起先后于全球计算机视觉顶会ICCV及CVPR举办,吸引了包括微软、Facebook、斯坦福大学、阿里巴巴、百度等众多顶尖机构踊跃参与,并形成了国际上规模最大、认可度最高的VQA(Visual Question Answering)数据集,其包含超20万张真实照片、110万道考题。
VQA是AI领域难度最高的挑战之一。在测试中,AI需根据给定图片及自然语言问题生成正确的自然语言回答。
这意味着单个AI模型需融合复杂的计算机视觉及自然语言技术:首先对所有图像信息进行扫描,再结合对文本问题的理解,利用多模态技术学习图文的关联性、精准定位相关图像信息,最后根据常识及推理回答问题。
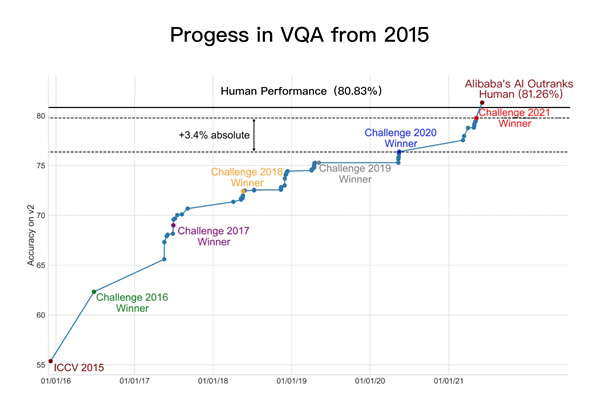
VQA技术自2015年的进展
今年6月,阿里达摩院在VQA 2021 Challenge的55支提交队伍中夺冠,成绩领先第二名约1个百分点、去年冠军3.4个百分点。两个月后,达摩院再次以81.26%的准确率创造VQA Leaderboard全球纪录,首次超越人类基准线80.83%。
VQA的核心难点在于对多模态信息进行联合推理认知,即在统一模型里做不同模态的语义映射和对齐。
据了解,达摩院NLP及视觉团队对AI视觉-文本推理体系进行了系统性的设计,融合了大量算法创新,包括多样性的视觉特征表示、多模态预训练模型、自适应的跨模态语义融合和对齐技术、知识驱动的多技能AI集成等,让AI“读图会意”水平上了一个新台阶。
VQA技术拥有广阔的应用场景,可用于图文阅读、跨模态搜索、盲人视觉问答、医疗问诊、智能驾驶等领域,或将变革人机交互方式。
报道显示,这不是阿里达摩院第一次在AI关键领域超越人类基准。2018年,达摩院曾在斯坦福SQuAD挑战赛中历史性地让机器阅读理解首次超越人类,引发海外媒体关注。
今年以来,达摩院在AI底层技术领域动作频频,先后发布了中国科技公司中首个超大规模多模态预训练模型M6及首个超大规模中文语言模型PLUG,并开源了历经3年打造的深度语言模型体系AliceMind(https://github.com/alibaba/AliceMind),其曾登顶 GLUE等六大国际权威NLP榜单。
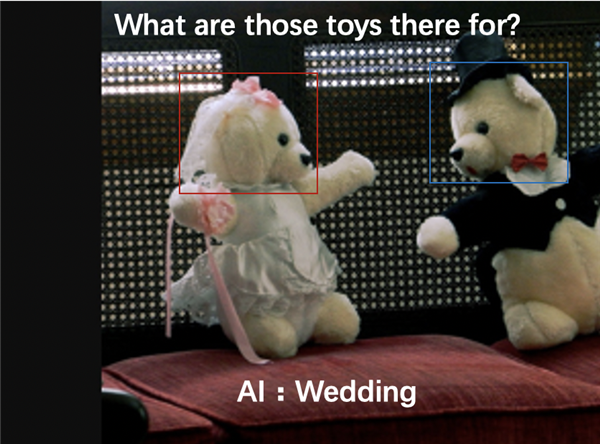
VQA考题列举,根据有礼服装饰的小熊玩具照片及问题“这些玩具用来做什么的?”达摩院AliceMind成功推理出一个可能的答案“婚礼”

版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“物联之家 - 物联观察新视角,国内领先科技门户”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场。
延伸阅读





 纽约一男子利用苹果AirTags追回被盗滑板车
历经6年 AI终于在“读图会意”上超越人类
纽约一男子利用苹果AirTags追回被盗滑板车
历经6年 AI终于在“读图会意”上超越人类
版权所有:物联之家 - 物联观察新视角,国内领先科技门户