
我曾经写过一篇文章《和Wall-E一起仰望星空》,里面介绍了机器学习在大数据天体物理时代的应用,其高效性、自动化、准确性都给人们留下了深刻的印象。
看上去,人工智能也许能够帮助天文学家有效地解决大数据天体物理时代所面临的难题。然而,人工智能真的是万能的么?本文将从目前机器学习的局限性探讨一下机器学习在天体物理中的应用范围。
01 刚需:大数据天体物理时代到来
随着观测技术的发展,天文数据呈指数型增长。例如,著名的斯隆巡天(The Sloan Digital Sky Survey)[1]开始于2000年,观测到了约300万个天体,数据量大约是40TB。而目前正在运行的暗能量巡天(The Dark Energy Survey)[2]的数据量至少是斯隆巡天的100倍。未来欧洲的欧几里得巡天(Euclid)[3]以及美国的大视场时空巡天(LSST)[4]则会把数据量推到惊人的50PB和200PB(1PB=1024TB)。
仅仅是可观测星系一种天体的样本数目,就将达到数十亿。因此,以往传统编程加人工处理方式的效率已经不足以应付这样庞大的数据量了。例如,把上百亿的星系按照哈勃星系图表(图1)分类的工作量就多到让人望而却步,这还仅仅是天体物理学研究的基本操作。
也就是说,高效的自动化数据处理将成为刚需。幸好人工智能技术在过去的十几年里有了突飞猛进的发展,比如图样识别技术已经可以快速地把互联网上的图片进行分类。天文学家们受此启发,开始把人工智能领域里的相关技术应用到天文数据的自动化处理中。
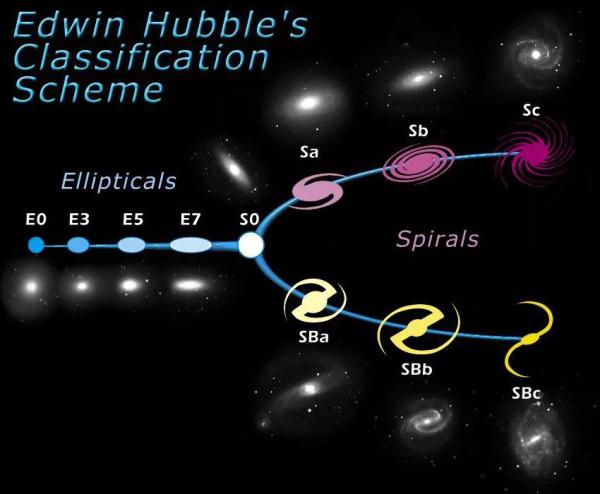
图1. 哈勃星系分类图表 ,最左侧分支(E)是椭圆星系,由左到右椭率逐渐增大。S0代表椭圆星系和漩涡星系的临界点。Sa,b,c分支代表常规漩涡星系,由a到b星系的光度中漩臂占的比重越来越大。SB分支代表具有棒结构的漩涡星系,由a到b的排序不只考虑了光度比还考虑的悬臂的开放程度。图片来源:https://en.wikipedia.org/wiki/Hubble_sequence
02 应用:分类、回归与生成
著名科学家赫伯特·西蒙(Herbert Simon,1975年图灵奖和1978年诺贝尔经济学奖得主)给机器学习下过定义——“机器学习是计算机程序通过摄取数据来自行改进性能的过程”。机器学习和传统程序根本的不同就是编程逻辑:机器学习的理念是归纳法,而传统编程更倾向于演绎法。
例如,如果想用传统编程方法对星系的形状分类,我们需先测量星系的形状参数,然后设定阈值,再根据形状参数和阈值的关系对星系分类;而机器学习的逻辑则是:先建立一个普适的模型,不提供特定参数或阈值,只输入星系图像和归类标签,这个模型就会根据输入的数据自我调整,从而演化成一个可用于星系形状分类的分类器。图2展示了传统程序和机器学习程序工作流程的差异。

图2. 传统编程和机器学习编程逻辑的差异。图片来源:
https://www.futurice.com/blog/differences-between-machine-learning-and-software-engineering/
眼下,天文学家主要应用机器学习解决分类、回归、生成等分体,成功案例包括星系形状分类和指定天体辨识(图3)、天体物理现象的快速自动化建模(图5)以及仿真图像的生成(图6)。综合来看机器学习在解决天体物理学问题上具有以下优点:1)覆盖范围广,普适性好;2)数据驱动,上限明显高于传统方法;3)开发难度越来越低,移植性好。这些优点使得机器学习的方法在天体物理尤其是大数据时代的天体物理中越来越流行,几乎在各个天体物理学领域甚至各个科学领域都能看到其身影。

图3. 应用监督学习和非监督学习进行星系形状分类的范例。上图为监督学习分类结果的范例[5],下图为非监督学习星系分类结果的范例[6]。两个方法都能比较好地根据形状对星系进行分类了,如果有兴趣了解更多细节,请访问图片来源链接里的论文(文末参考文献,下同)。
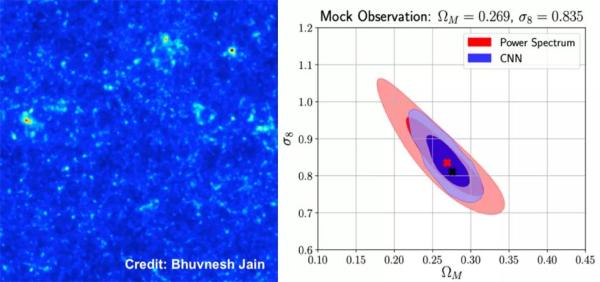
图4. 应用机器学习解决“回归问题”的实例。左图为宇宙中的投影物质分布示意图,右图为机器学习的方法根据宇宙中的投影物质分布预言的宇宙学参数[7]。这个应用的基本思想是通过机器学习的算法建立起左图和由图中宇宙学参数的对应关系,这样在将来有新的物质分布的数据的时候,只要输入训练好的模型中,就可以快速地返回对应的宇宙学参数了。
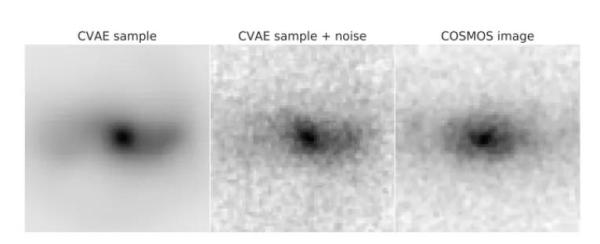
图5. 机器学习算法生成的仿真星系图像与真实图像的对比[8]。左图为机器学习生成的无噪音漩涡星系,中图为添加噪音之后的仿真图像,右图为哈勃望远镜所观测到的图像。生成尽可能真实的数值模拟的图像有助于天文学家测试和校正数据处理软件和科学建模软件。
03 短板:门槛、数据与黑盒子
然而,机器学习并非无所不能。首先其超高的计算量和特别的硬件需求使其入门门槛要高于传统方法。另外,模型设计非常复杂,要投入大量的人力、物力和时间来开发新算法及模型,大部分人只能使用现有的模型。而且,机器学习是一个随机的过程,结果的统计性是自洽的,但无法在个体结果上实现多次完美重现。
例如,应用机器学习实现分类操作时,小部分目标天体每次的分类结果都会不一样;应用机器学习实现回归计算时,每次预言的参数也都不是可重复的固定值,尽管不确定性很小。因此,应用机器学习研究天体物理学问题时,有明确一对一关系的物理过程(如星系动力学仿真和引力透镜光线追踪仿真等)依然需要传统方法来实现。
其次,机器学习是数据驱动的,所以缺少数据的科学问题要谨慎采用此方法,尤其是数据在参数空间的覆盖范围不够完备的时候,机器学习将给出有偏差的结果。当然,可以使用数值模拟的方式来改进数据的完备性和多样性,但这又导致机器学习给出的结果强烈依赖仿真数据的生成模型,因此应用机器学习解决此类问题的时候,需要尽可能详尽地设计仿真过程从而创建合理的训练样本。
另一方面,在数据体量满足条件的时候,缺少优质数据的科学问题也不太适合采用机器学习来解决,因为大量的劣质数据会导致机器学习模型对噪音(非真实优质的数据)做出响应,从而给出可信度很高的错误结果。解决此类问题时,对数据谨慎地预筛选和后筛选是必要的,以尽量避免“错进错出(Garbage in, Garbage out)”现象。
最后,也是最重要的:机器学习算法的不可解释性是被人诟病最多的短板,因此机器学习一直被比喻成黑盒,形象的地描述了机器学习算法对相关性敏感,但极其欠缺因果性的解释。
目前为止,机器学习,尤其是深度学习的唯一真正成功之处是在给定大量人类注释数据的情况下,能够使用连续的几何变换将空间X映射到空间Y,然而至于为什要从X映射到Y还需要科学家自己把控。此外,从X映射到Y的具体细节也需要更深入的研究。
相关研究[9]已经尝试用谷歌的Deep-Dream[10]工具包研究星系团质量重构过程中对特定数据点的敏感性(图6),微软的InterpretML[11]工具包则专注于神经网络模型中各部分的逻辑关系和数据流向(图7),这两个尝试可以被看成“向黑盒子照入光”,帮助人们更好地理解其工作原理,当然结果仍很初步,离完全理解“黑盒子”还有很长的路要走。希望随着对机器学习工作逻辑研究的深入,人类能最终打开黑盒,让机器学习帮助科学家更好地探索宇宙。
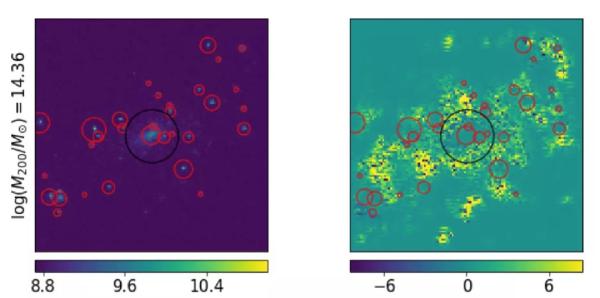
图6. 应用深度学习算法基于星系团的光度信息重构星系团的总质量分布的过程中,星系团光度场中数据点对重构结果贡献的权重示意图。
左侧为星系团的广度分布(恒星粒子分布)[9],其中黑圈圈出星系团的中心星系的位置,红圈圈出星系团的成员星系;右侧为Deep-Dream[10]处理后的结果,黄色的区域代表对结果贡献比较大的数据点 。

图7. 机器学习模型解释软件InterpretML简介[11]。
04 总结:有效、有选择、有未来
大数据天体物理时代,机器学习能有效地帮助天文学家完成了海量数据的挖掘工作。但机器学习并不是万能的钥匙,不能盲目地应用机器学习去解决所有天文学问题,尤其是在问题范围不明确、数据体量不足以及数据质量不高的情况下。
另外,不可解释性是机器学习方法目前最大的短板,因此根据机器学习的结果下因果性结论的时候要尤为谨慎。已经有一些先驱性工作尝试解释机器学习结果与数据的因果关系以及机器学习模型内部的逻辑关系,希望随着此类研究的深入,人类能最终打开黑盒,让机器学习也能从事推理和抽象相关的科研工作。
不过话说回来,真到那个时候,天文学家又将扮演何种角色呢?会不会成为失业的人群?欢迎留下你的看法。
参考文献:
[1] https://www.sdss.org/
[2] https://www.darkenergysurvey.org/
[3] https://www.euclid-ec.org/
[4] https://www.lsst.org/
[5] Dieleman, S. et al., Rotation-invariant Convolutional Neural Networks for Galaxy Morphology Prediction, 2015, MNRAS, Vol. 450, Issue 2, p.1141-1459
[6] Hocking, A. et al., An automatic taxonomy of Galaxy Morphology Using Unsupervised Machine Learning, 2018, MNRAS, Vol. 473, Issue 1, p.1108-1129
[7] Fluri, J. et al., Cosmological Constraints from Noisy Convergence Maps through Deep Learning, 2018, Physical Review D, Vol. 98, Issue 12, id.123518
[8] Ravanbakhsh, S. et al., Enabling Dark Energy Science with Deep Generative Models of Galaxy Images, 2017, AAAI-2017, Proceedings, id.14765
[9] Yan, Z. et al, Galaxy Cluster Mass Estimation with Deep Learning and Hydrodynamical Simulations, 2020, MNRAS, Vol. 499, Issue 3, pp.3445-3458
[10] https://github.com/google/deepdream
[11] https://github.com/interpretml/interpret
作者简介
李楠
2013年在中国科学院大学年获得天体物理学博士,现中国科学院国家天文台副研究员,主要研究兴趣为机器学习在天体物理中的应用、应用引力透镜效应研究星系宇宙学问题。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“物联之家 - 物联观察新视角,国内领先科技门户”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场。
延伸阅读

 5G技术对这20个产业的冲击
人工智能是大数据天体物理时代的万能钥匙吗?
5G技术对这20个产业的冲击
人工智能是大数据天体物理时代的万能钥匙吗?
版权所有:物联之家 - 物联观察新视角,国内领先科技门户