量子计算机虽然仍处于起步阶段,但正在影响已在传统计算机上运行的新一代模拟技术,量子计算机现在可借助 NVIDIA cuQuantum SDK 进行加速。

在 Steve Jobs 发布一台可以放入口袋的计算机的 27 年前,物理学家 Paul Benioff 发表了一篇论文,表明理论上可以构建一个更小更强大的系统——一个量子计算机。
Benioff 于 1980 年描述的概念是利用亚原子物理学命名,这个概念依然在驱动着今天的研究,包括努力创造下一个计算领域大事件:一个可以在某些方面让电脑看起来像算盘的古朴的系统。
诺贝尔物理学奖得主 Richard Feynman 通过引人入胜的演讲,为广大听众带来了物理学,他帮助建立了这个领域,勾勒出此类系统如何比传统计算机更有效地模拟离奇的量子现象。
量子计算是什么?
量子计算使用亚原子粒子的物理学领域来执行复杂的并行计算,从而取代了当今计算机系统中更简单的晶体管。
量子计算机使用量子比特计算,计算单元可以打开,关闭或之间的任何值,而不是传统计算机中的字符,要么打开,要么关闭,要么是 1,要么是 0。量子比特居于中间态的能力(称为“态叠加”),这为计算方程增加了强大的功能,使量子计算机在某种数学运算中更胜一筹。

量子计算机的作用
量子计算机可以通过量子比特进行计算,这种计算过程需要耗费传统计算机无限长的时间,有时甚至根本无法完成。
例如,如今的计算机使用 8 位表示介于 0 到 255 之间的任何数字。得益于态叠加原理,量子计算机可以使用八个量子比特同时表示 0 到 255 之间的每个数字。
这是一项与计算中的并行性类似的功能:所有可能性都是一次性计算,而非按顺序计算,从而大幅增加速度。
因此,经典计算机每次执行一个长除法计算以分解一个庞大的数字,而量子计算机却可以仅通过一个步骤获得答案。砰!
这意味着量子计算机可以重塑整个领域,例如密码学,这些领域均基于对当今不可能处理的庞大数据进行分解。
微型模拟的一大作用
这可能只是个开始。一些专家认为,量子计算机将突破目前阻碍化学、材料科学以及任何涉及量子力学纳米级大小的世界模拟的极限。
量子计算机甚至可以帮助工程师对他们在当今最小的晶体管中开始发现的量子效应进行更精细的量子效果模拟,从而延长半导体的使用寿命。
事实上,专家表示量子计算机最终不会取代经典计算机,它们将相互补充。有些人预测,量子计算机将用作加速器,就像 GPU 加速当今的计算机一样。
量子计算是如何工作的?
不要指望用从当地电子商店的打折箱里回收的零件来搭建自己的量子计算机,像自己动手组装一台个人电脑一样。
目前,少数运行中的系统通常需要冷藏,以在绝对零度以上一点创造工作环境。他们需要这种寒冷的计算环境来处理为这些系统提供动力的脆弱的量子态。
要说构建量子计算机有多难,一个原型是在两个激光器之间悬浮一个原子以创建一个量子比特。您可以在家里的工作室试试!
量子计算创造了纳米级别非常强大却有着致命弱点的东西-量子纠缠,那是当一个量子态中存在两个或更多的量子比特的情况,这种情况有时由波长仅一毫米的电磁波来测量。
如果波的能量稍微大一些就会失去量子纠缠或叠加态,或者两者同时失去。结果就会出现一种叫做量子退相干的噪音状态,在量子计算中等同于电脑蓝屏死机。
量子计算机现在的状态如何?
阿里巴巴、Google、Honeywell、IBM 、IonQ和Xanadu等少数几家公司都运营着早期几代量子计算机。
如今,他们提供了数十个量子比特。但噪音可能较高,导致它们有时不稳定。。如要可靠地解决实际问题,系统需要数万或数十万个量子比特。
专家认为,要进入量子计算机真正有用的高保真时代,还得需要几十年。

量子计算机正慢慢向商业用途发展。(来源:Lieven Vandersypen 在 ISSCC 2017 上的演讲。)
关于何时达到所谓量子计算霸权(量子计算机执行经典计算机无法执行的任务的时间)的预测是业界热烈讨论的问题。
加速量子电路模拟
好消息是 AI 和机器学习领域聚焦于 GPU 等加速器,这些加速器可以执行量子计算机用量子比特计算的许多类型的运算。
现在,经典计算机已经找到了使用 GPU 实现量子模拟的方法。例如,NVIDIA 在我们的内部 AI 超级计算机 Selene上进行前沿的量子模拟。
NVIDIA 在 GTC 主题演讲上宣布推出 cuQuantum SDK,目的是加速在 GPU 上运行的量子电路模拟。早期研究表明,cuQuantum 能够提供许多量级的加速。
SDK 采用一种不可知论的方式为用户提供了可以选择的最适合其方法的工具。例如,态向量可提供高保真结果,但其内存需求会随着量子比特数量的增大呈指数级增长。
这会在如今最大的传统超级计算机创造约 50个量子比特的实际限制。不过,我们已经(见下文)看到使用 cuQuantum 加速使用这种方法的量子电路模拟的显著结果。
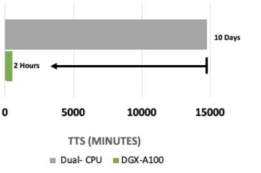
态向量:1,000 个电路,36 个量子比特,深度 m=10,复杂度 64 | CPU:双 AMD EPYC 7742 上的 Qiskit | GPU:DGX A100 上的 Qgate
来自 Jülich 超级计算中心的研究人员将在 GTC session E31941深入讲解态向量法的工作(免费注册)。
一个较新的方法是张量网络模拟,它使用更少的内存和更多的计算来执行类似的工作。
利用这种方法,NVIDIA 和加州理工学院使用运行在 NVIDIA A100 Tensor Core GPU 上的 cuQuantum 完成了对最先进的量子电路模拟器的加速。在Selene 上,这个实验在 9.3 分钟便从 Google Sycamore 电路的全电路模拟中生成了一个样本,而18 个月前,专家认为需要使用数百万个 CPU 核心花费数天时间才能完成这项任务。

网络 - 53 个量子比特,深度 m=20 |CPU:双 AMD EPYC 7742 上的 Quimb库 | GPU:DGX-A100 上的 Quimb库
加州理工学院的研究科学家 Johnnie Gray 说:“通过使用 Cotengra/Quimb 包、NVIDIA新发布的 cuQuantum SDK 和 Selene 超级计算机,我们在10 分钟内生成了 Sycamore 量子电路样本,深度m=20”。
加州理工学院化学教授 Garnet Chan 表示:“这为量子电路模拟性能设定了基准,并将有助于提升我们验证量子电路行为的能力,从而推动量子计算领域的发展。”Garnet Chan 教授的实验室是这项工作的主办方。
NVIDIA 预计,cuQuantum 的性能提升和易用性将使其成为研究前沿每个量子计算框架和模拟器的基础元素。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“物联之家 - 物联观察新视角,国内领先科技门户”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场。
延伸阅读






 IDEC推出用于工业环境的智能RFID阅读器
IDEC推出用于工业环境的智能RFID阅读器
 2021年AI智能摄像机带来的新市场
2021年AI智能摄像机带来的新市场
版权所有:物联之家 - 物联观察新视角,国内领先科技门户