得益于台积电 3D 晶圆键合(wafer-on-wafer)技术,总部位于英国的 Graphcore 能够在不大刀阔斧改变自家专用 AI 处理器内核的情况下,显著提升其计算性能。Graphcore 高管称,名为 Bow 的新型组合芯片,将被率先投放于伦敦的某个地区。

Bow 与旧款 Colossus MK2 芯片均使用了 TSMC N7 工艺制造(图自:Graphcore)
在电压低于前身的情况下,Bow 还可运行得更快速(1.85 vs 1.35 GHz),意味着计算机迅雷神经网络的速度提升了 40%、同时能耗降低了 16% 。更棒的是,用户无需修改软件,即可获得这些益处。
Graphcore 首席技术官兼联合创始人 Simon Knowles 表示:“我们正在进入一个先进封装的时代,通过将多个硅芯片组装在一起,我们得以在其它方面弥补性能增长不断放缓的摩尔定律”。
作为比较,英特尔Foveros 方案选择了将切割后的芯片连接到其它芯片或晶圆上。而台积电的 SoIC WoW 技术,则是将两个完整的芯片晶圆键合到了一起。
每个芯片上的铜焊盘在晶圆对齐时匹配,再将两个晶片叠压到一起时让焊盘熔断。我们可将至视作某种冷焊,接着将顶部晶圆削薄到仅数微米,最后将键合晶圆切割成芯片。
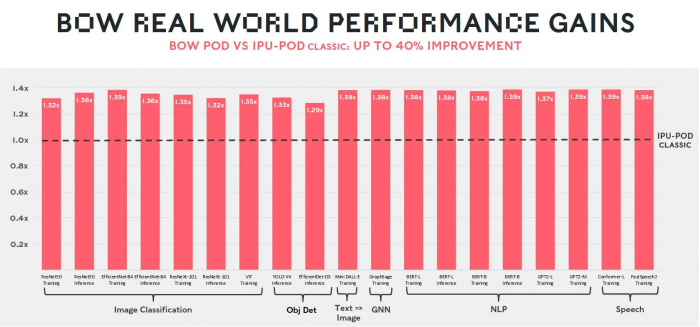
BOW 实测性能增益
在 Graphcore 的案例中,其在一块晶圆上填满了该公司的第二代 AI 处理器,拥有 1472 个智能处理单元(IPU)和 900MB 片上缓存。
这些处理器已在商业系统中得到应用,并在最近一次 MLPerf 基准测试中交出了相当不错的答卷。
至于另一个晶片,其拥有一套相应的供电芯片(不包含晶体管或其它有源器件),配备了电容并通过硅通孔(TSV)来垂直连接。
值得一提的是,电容器组件形成在硅片上深且窄的沟槽中(类似 DRAM)。通过将这些电荷储存组件放置在靠近晶体管的位置,以实现更平滑的功率传输,从而使 IPU 内核在较低电压下运行得更快。
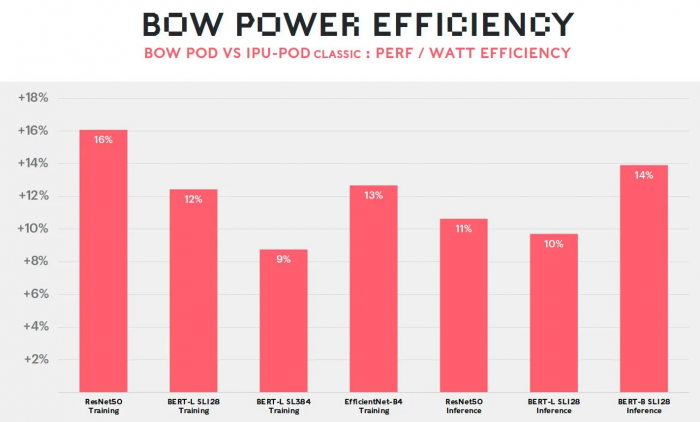
能效增益
若缺乏这一方案,Graphcore 就必须将 IPU 工作电压提升到更高,才能维持 1.85 GHz 的工作频率。此外借助电源芯片,也可助力其达成该时钟频率、并减少能源开销。
Graphcore 高管补充道,Wafer-on-Wafer 技术使得芯片之间的链接密度可高于将单个芯片连接到晶圆上,但也面临一批晶圆中难免有少数存在缺陷的问题。
通过键合两片晶圆,会使得成品芯片的缺陷率翻番。为了缓解这种情况的发生,Graphcore 选择了一套机智的应对方法 —— 与其它 AI 处理器一样,IPU 由许多重复、冗余的处理器内核和其它部分组成。
公司联合创始人兼首席执行官 Nigel Toon 指出,任何缺陷都可通过内置的保险电路,让它们与 IPU 的其余部分隔离开来。
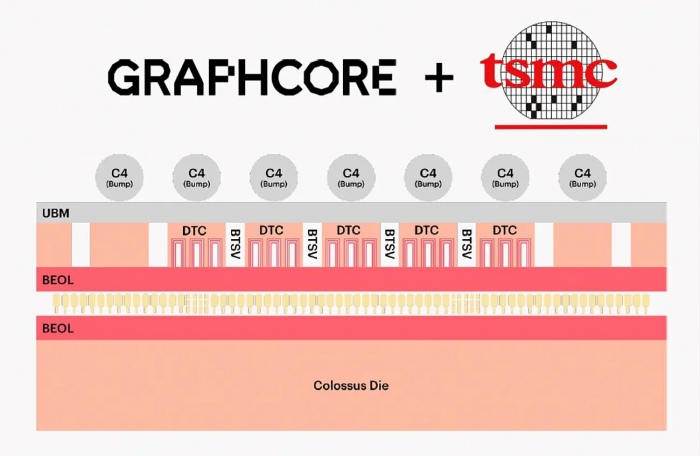
TSMC 晶圆键合工艺的层级示意
有趣的是,尽管 BOW 尚未在供电芯片上堆砌晶体管,但 Simon Knowles 暗示道 —— 当前工作只能算是迈出了第一部,该公司将在不久的将来“走得更远”。
此外该公司披露了一些计划,比如将打造可训练“人脑规模”人工智能的超级计算机 —— 在神经网络中具有数百亿的参数数量级。
而以英国数学家 I.J.“Jack”Good 命名的“Good 计算机”—— 由 512 个系统 / 8192 个 IPU)、大容量存储、CPU 和网格组成 —— 将能够处理超过 10 ExaFlops(千亿亿次)的浮点运算。
在 4PB 内存和每秒超 10PB 带宽的加持下,Graphcore 预计每台超算造价在 1.2 亿美元左右,且有望于 2024 年交付使用。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“物联之家 - 物联观察新视角,国内领先科技门户”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场。
延伸阅读






 边缘 AI 正在改变工业计算的世界
边缘 AI 正在改变工业计算的世界
 工信部部长肖亚庆:进一步扩大新能源汽车等领域消费
工信部部长肖亚庆:进一步扩大新能源汽车等领域消费
版权所有:物联之家 - 物联观察新视角,国内领先科技门户