由 Amazon Web Services 的 Annapurna Labs 部门设计的 Graviton 系列 Arm 服务器芯片可以说是当今数据中心市场上产量最大的 Arm 服务器芯片,并且它们恰好拥有一个且只有一个客户,也是直接客户——AWS。
这两个事实说明了Annapurna Labs 为创建更强大的 Arm 服务器处理器所做的设计选择,并且它们区别于其他两种针对当今市场上服务器的合理大容量 Arm 服务器 CPU,即富士通的 A64FX 处理器和Ampere Computing 的 Altra 家族。还有其他针对特定地区和用例的 Arm 服务器芯片正在开发中,这似乎总是存在,但它们看起来都不会像 Graviton 和 Altra 系列那样成为批量产品;富士通 A64FX 是量产产品,因为有使用它的主机——日本理研实验室的“Fugaku”超级计算机。
AWS 在拉斯维加斯的 re:Invent 大会上推出了第三代 Graviton3 服务器芯片,我们未能参加,我们在 12 月根据当时可用的摘要信息对处理器进行了概述,承诺在提供更多来自技术会议的信息时回过头来进行更深入的研究。该信息现在可以从云巨头负责 Graviton 实例的高级首席工程师 Ali Saidi 的演示中看到。Saidi 更详细地介绍了预览中的 64 核、550 亿晶体管 Graviton3 与其前身——2018 年 11 月预览的 16 核、50 亿晶体管 Graviton 和 2019 年 11 月预览的64 核、300 亿晶体管 Graviton2 的不同之处。AWS 需要几个月的时间才能使 Graviton 芯片全面生产,一旦使用 Graviton3 芯片的 EC2 服务上的 C7g 实例全面生产并停止预览,我们就会知道更多。
首先,Saidi 谈到了为什么 AWS 甚至费心制造自己的服务器 CPU,也许制造自己的“Nitro”DPU 来卸载 X86 服务器处理器的管理程序以及安全处理和存储以及网络虚拟化似乎就足够了。
“构建我们自己的芯片确实让我们能够在各种层次上进行创新,更快地创新,提高安全性,并提供更多价值,”Saidi解释道。“在创新方面,能够构建芯片和服务器,并让编写软件的团队在一个屋檐下进行,这意味着创新速度更快,我们可以跨越传统界限。我们也可以为我们的需要制造芯片。我们可以将它们专门用于我们正在尝试做的事情,而不必添加其他人想要的功能。我们可以只为我们认为将为我们的客户提供最大价值的东西构建它们,而忽略那些实际上不是的东西。我们得到的第三件事是速度。我们可以控制项目的开始、进度和交付。我们可以并行化硬件和软件开发,并使用大规模的云来进行构建芯片所需的所有模拟。最后,操作。通过运行 EC2,我们可以深入了解操作,我们可以将功能放入芯片中,以执行诸如刷新固件以解决问题或增强功能等操作,而不会打扰在机器上运行的客户。”
显然,Graviton 的努力不仅仅是从英特尔和 AMD 那里获得更便宜的 X86 服务器芯片价格——尽管它也是如此,即使Saidi没有提到它。但只要 AWS 在其云中托管大量 X86 客户,它就会为其云客户购买 Xeon SP 和 Epyc 处理器,用于他们创建的那些不易移植到 Arm 架构并因此从 20 Graviton 系列在 EC2 上的 X86 实例上显示了 1% 到 40% 的性价比优势,涵盖了广泛的工作负载和场景。
没有人确切知道 AWS 队列中有多少 Graviton 处理器,但我们所知道的是 Graviton 处理器以某种方式在 23 个不同的 AWS 区域和十几种不同的 EC2 实例类型中可用。

AWS拥有超过475不同的EC2实例类型,其在CPU,内存,存储,网络和加速器配置方面运行域,以及Graviton实例是明显的一个很小的部分品种EC2 实例。24 个地区中有 23 个至少拥有一些 Graviton 处理器,这或许更能说明 Graviton 在 AWS 机群中的流行——但不一定。我们认为可以诚实地说,与运行 Web 式工作负载的 X86 处理器相比,性价比提高了 30% 到 40%,并且随着产品线的发展,Graviton 芯片的功能越来越强大,我们认为 AWS 软件工作负载的一部分越来越大与在运行 Windows Server 或 Linux 的 X86 处理器上运行其他人的应用程序无关——比如无数的数据库和 SageMaker AI 服务——最终将使用 Graviton,从而降低这些服务的总体成本,同时保持 AWS 的利润。
事实上,Saidi 表示,对于 AWS 兜售的 PaaS 和 SaaS 服务,如果客户在注册服务时没有特别指定实例类型,他们将在该服务下获得一个 Graviton 实例。这表明 AWS 队列中有相当多的 Graviton 服务器。事实上,在今年的 Prime 会员日,安装在 EC2 服务下的 Graviton2 实例支持了亚马逊在线零售业务使用的十几个核心零售服务。曾经支持跨 Amazon 内部零售数据服务的查找、查询和联接的关键服务 Datapath 从 X86 服务器移植到由超过 53,000 个基于 Graviton2 的 C6g 实例组成的三区域集群。
这就是事实,这可能也是为什么英特尔和 AMD 需要在 15 年前构建自己的云,而不是让戴尔、惠普企业和 VMware 尝试并失败的原因。在不久的将来,CPU 将成为数据中心的弱势群体。
这也是英伟达今年与 AWS 合作使其 HPC SDK 在其基于 Graviton 处理器的 ParallelCluster 超级计算服务上运行的原因,这将允许使用 OpenMP 的 C、C++ 和 Fortran 程序并行化应用程序以在 Graviton 实例上运行,并且这也是 SAP 与 AWS 合作将其 HANA 内存数据库移植到 Graviton 实例并将这些实例用作 SAP 自己的托管在 AWS 上的 HANA 云服务的基础的原因。
探索Graviton3内部
Saidi 的演讲比 re:Invent 主题演讲详细得多,实际上展示了 Graviton3 封装的一个镜头,这是我们听说的小芯片(chiplet)设计。这是显示 Graviton3 封装的幻灯片:

这个die顶部的特写图像放大了一点,但原始图像是模糊的——所以不要怪我们。这与 Graviton3 封装的图像一样好。
下面的示意图让 Graviton3 上的小芯片如何分解其功能更加清晰:
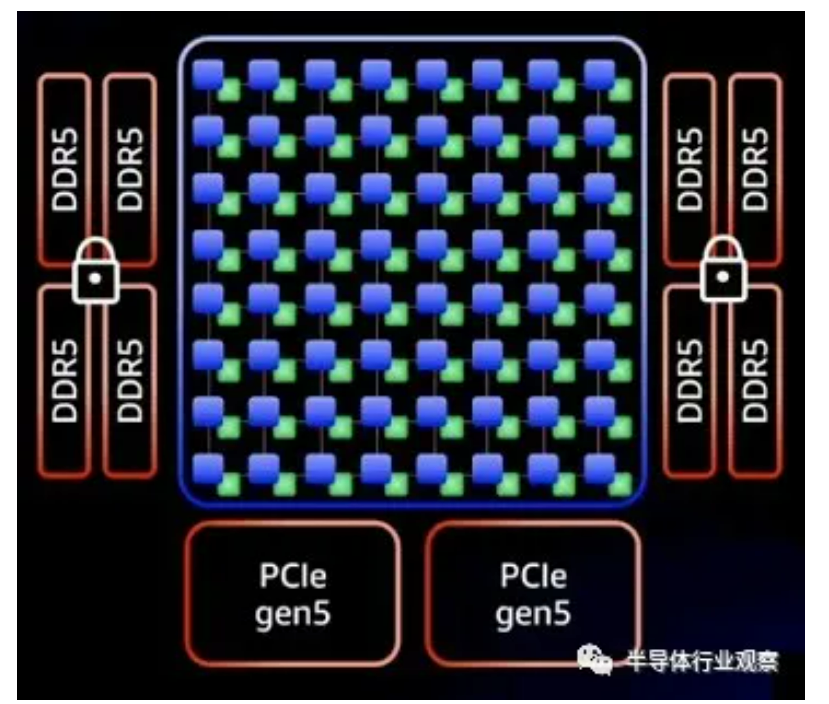
Annapurna Labs 团队没有像 AMD 使用“Rome”Epyc 7002 和“Milan”Epyc 7003 X86 服务器芯片那样拥有中央 I/O 和内存芯片,然后围绕它的小芯片内核,而是保留了所有 64 个内核在中心的 Graviton3 上,然后断开与这些内核分离的 DDR5 内存控制器(具有内存加密)和 PCI-Express 5.0 外围控制器。封装底部有两个 PCI-Express 5.0 控制器和四个 DDR5 内存控制器,封装两侧也各有两个。(这是第一个支持 DDR5 内存的服务器芯片,其带宽比当今服务器中常用的 DDR4 内存高 50%。当然,今年其他芯片也会跟进。)
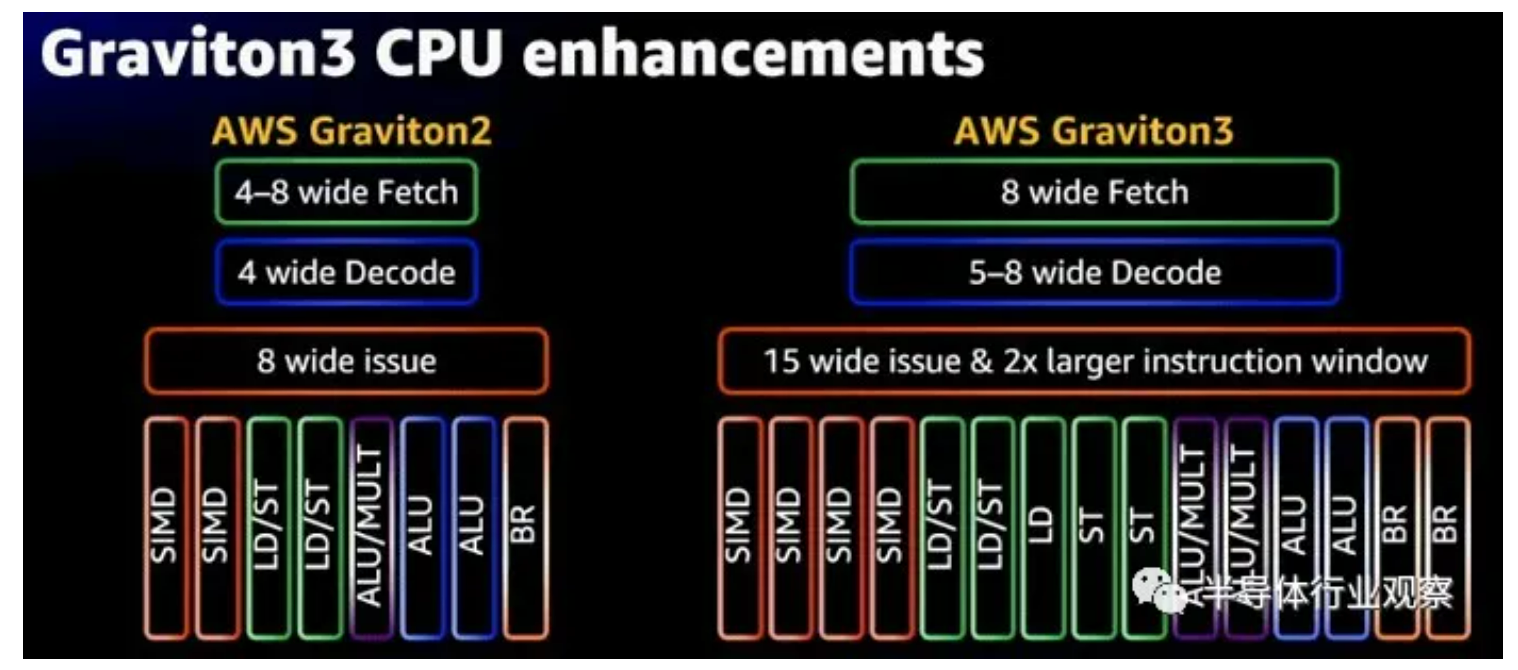
与 Graviton2 相比,Graviton3 增加了 250 亿个晶体管,其中大部分,据Saidi 说,是为了加强内核,正如 AWS 公用事业计算高级总裁 Peter DeSantis已经在他的主题演讲中解释的那样,这个想法是通过加强pipeline让内核做更多种类的工作以及更多的工作。像这样:
Graviton2 基于 Arm Holding 的 Neoverse “Ares”N1 内核设计的,他们在去年 4 月又发布了“Perseus”V1 和“Zeus”N2 内核。正如我们已经指出的,与一些人的看法相反,我们认为 Graviton3 是基于 N2 核心,而不是 V1 核心。AWS 尚未确认正在使用什么核心。我们做了大量尝试,试图去确认 Annapurna Labs 在 Graviton3 中的确使了 N2 核心。我们公开承认,这是一个疯狂的猜测,因为红色粗体显示的项目是:

无论如何,回到pipeline方面。Saidi 解释说,与 Graviton2 的 N1 内核相比,Graviton3 内核的性能提高了 25%——我们认为这意味着更高的每时钟指令数或 IPC。Graviton3 以稍高的时钟速度运行(2.6 GHz,而 Graviton2 为 2.5 GHz)。据Saidi 说,核心的前端宽度是原来的两倍,而且还有一个更大的分支预测器。指令调度几乎是两倍宽,指令窗口是两倍宽,SIMD向量单元具有两倍的性能并支持SVE(富士通和Arm为富岳超级计算机的A64FX处理器发明的可变长度可伸缩向量扩展在 RIKEN)和 BFloat16(由 Google Brain 人工智能团队创建的创新格式)。每个时钟有两倍的内存操作来平衡这一切,还有一些增强的预取器,可以将两倍的未完成事务泵送到那些增强的 Gravition3 内核。核心的乘法器更宽,数量是其两倍。
与之前的 Graviton 和 Graviton2 内核以及 Ampere Computing Altra 系列中使用的内核一样,Graviton3 内核中没有试图提高吞吐量的超线程。不安全和更复杂的权衡不值得提高性能 - 至少对于 AWS 对其应用程序进行编码的方式。
AWS 没有做的另一件事是添加 NUMA 电子设备以将多个 Graviton3 CPU 连接到一个共享内存系统中,并且它也没有像英特尔通过电路和 AMD 使用其至强 SP 那样将核心块分解为 NUMA 区域,在罗马或米兰 Epyc 封装上使用八个核心tiles。内核与运行频率超过 2 GHz 且对分带宽超过 2 TB/秒的网格互连。
Graviton3 的一个优点是服务器,我们早在 12 月就谈到了这一点,AWS 正在创建一个自产的三节点、三插槽服务器,它有一个共享的 Nitro DPU,将它们连接到外部世界。像这样:
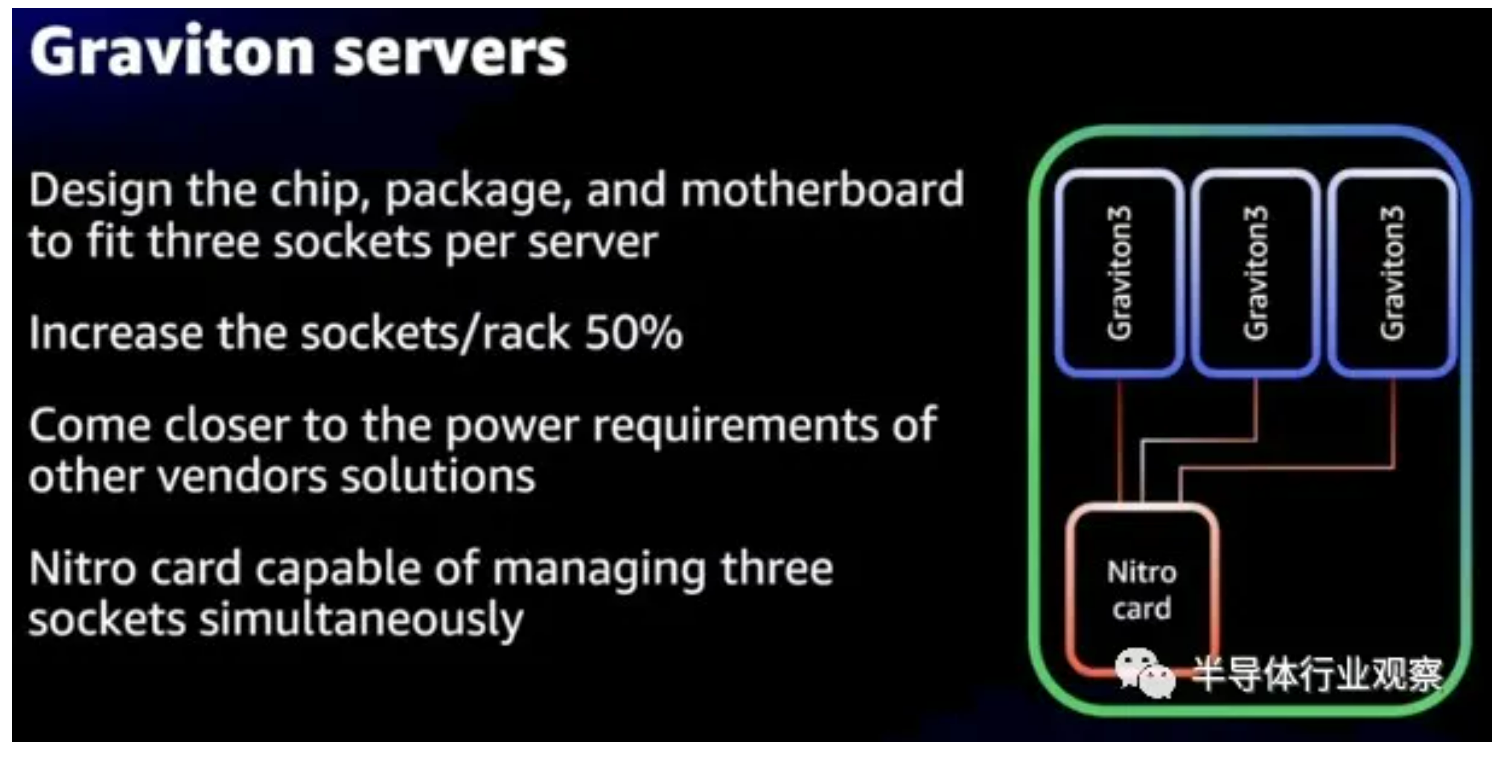
通过将大量 CPU 功能卸载到 Nitro DPU 并将一堆单插槽 Graviton3 节点塞到卡上,AWS 表示它可以将每个机架的插槽增加 50%——这大概意味着不会牺牲任何相关的性能来自 AMD 的 X86 处理器也处于合理的散热范围内。
我们已经在之前的 Graviton3 报道中讨论了一系列性能指标,但是这个显示 SPEC 2017 整数和浮点测试很有趣:
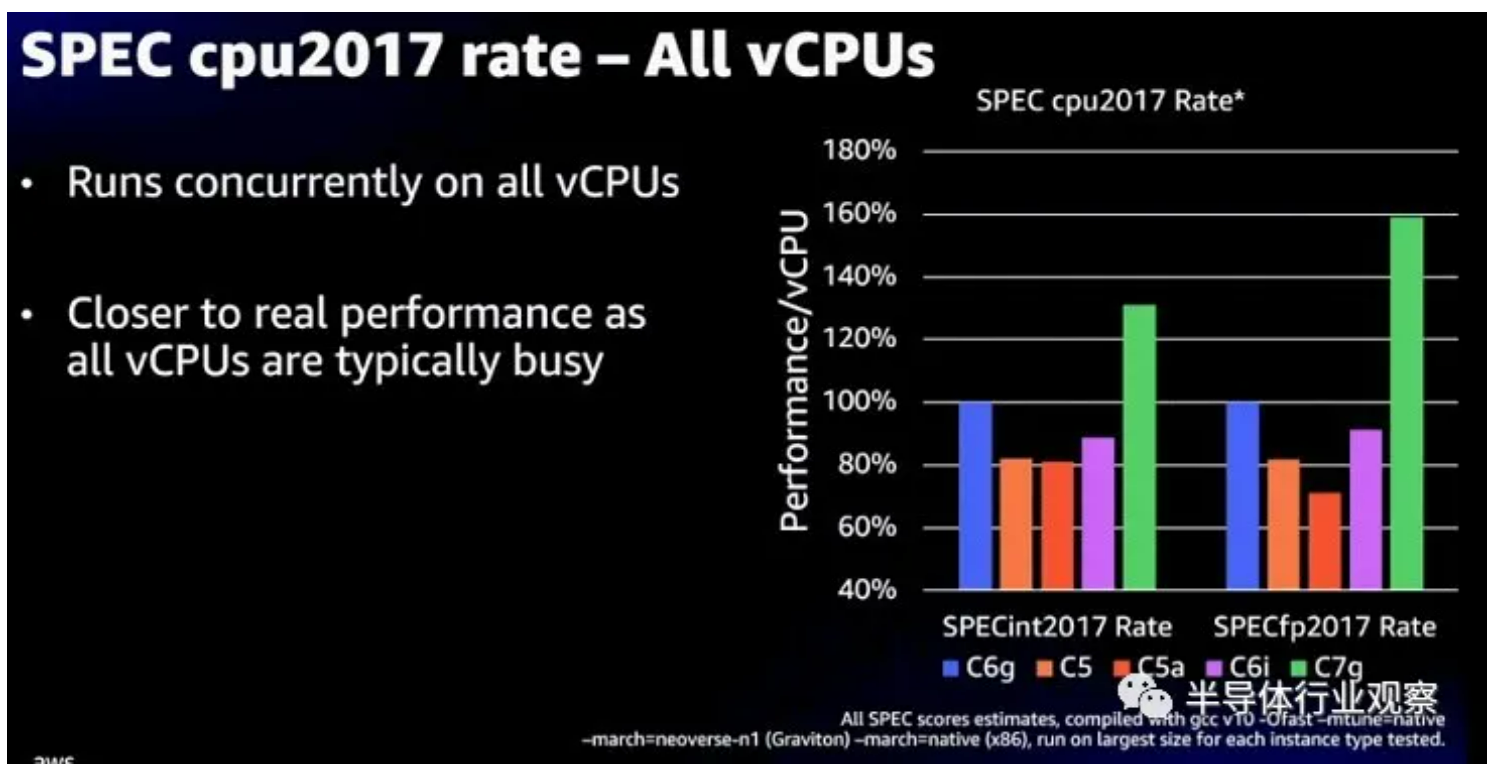
C7g 实例使用 Graviton3,C6g 使用 Graviton2,这表明前者的整数性能比后者高约 30%,浮点性能比后者高约 60%。C5 实例基于英特尔定制的“Cascade Lake”Xeon SP 处理器,而 C5a 实例基于 AMD 的 Rome Epyc 处理器。C6i 实例基于“Ice Lake”Xeon SP。我们更希望拥有这些实例的实际核心数和时钟速度以进行更好的比较,但很明显 AWS 想要给人的印象是 Graviton2 已经击败了竞争对手,而 Graviton3 确实做到了。
任何真正的比较都将着眼于整数和浮点工作的核心数、成本、散热和性能,然后权衡所有这些因素,以选择芯片以在实际应用中进行实际基准测试。SPEC 测试只是玩游戏的赌注。但他们不是游戏。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“物联之家 - 物联观察新视角,国内领先科技门户”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场。
延伸阅读





 分析师:MCU和电源管理芯片交期继续拉长
分析师:MCU和电源管理芯片交期继续拉长
 腾讯接入:微信支持数字人民币支付
腾讯接入:微信支持数字人民币支付
版权所有:物联之家 - 物联观察新视角,国内领先科技门户